本周在某次开会的时候,忽然收到了大量的 MySQL Seconds_Behind_Master 落后的报警轰炸(落后时间随机,几百到几万秒不等),但是当我们的值班 DBA 登录 MySQL 通过 show slave status\G 查看时,发现都是 0,通常我们认为这个时候复制是正常的。那么是什么情况导致了报警的发生呢?
DBA 值班同学也比较没有头绪,我们首先做了以下几件事情:
-
确认监控插件是否变更?收到的答复是没有;
-
我们自己是否有变更?收到的答复是没有。
事后打脸了,有一位同学做了报警策略的变更,从原 X 时间内只发送第 N 条报警修改成了 X 时间内只发送第 1 条报警。该策略的变更也会导致该报警的轰炸,但是他变更的时间是在报警轰炸之后,跟此次报警轰炸原因没有正相关;
- 登录多个实例确认都是误报后,先通告产品,明确是误报事件,让产品不用担心,等待 DBA 查明原因;
接下来我们会议正常进行,由某位 DBA 同学对此问题进行持续跟进,这个时候了解到某报警系统正在维护,猜测与他们有关系。但是即使是与他们有关系,这个落后的时间又是如何得来的呢?暂时 DBA 值班同学也没有很好的 GET 到头绪,DBA 老司机可能当时不是特别在状态,有点懵。
刚好会议环节进入非重点环节,偷偷转移精力排查了一下,做为 DBA 门外汉,首先想到的是我要确认是不是 MySQL show slave status 里真的出现了随机的落后数值,所以我做了最原始的一件事情:写了一个 2 秒执行一次 show slave status 的脚本对 Secons_Behind_Master 进行检查,果然在脚本执行了几分钟后出现了非 0 的数值,且是一个较大的超出实际线上情况的数值。(这里已经确认了是 MySQL 本身会有这个情况出现)
接下来怎么办呢?门外汉的第一反应当然是查手册啦(手册大多数时候都是解毒良药),几乎是没有耗费时间的,直接在 MySQL 官方文档里关于这个问题的非常重要的一句说明:
when the slave I/O thread is still queuing up a new event,
Seconds_Behind_Master may show a large value until the SQL thread
finishes executing the new event.
MySQL Replication 通常情况下有两个工作线程,I/O 线程用于获取 MySQL Master 的 Binlog,SQL 线程用于将获取到的 Binlog Events 在 Slave 从库上进行回放。
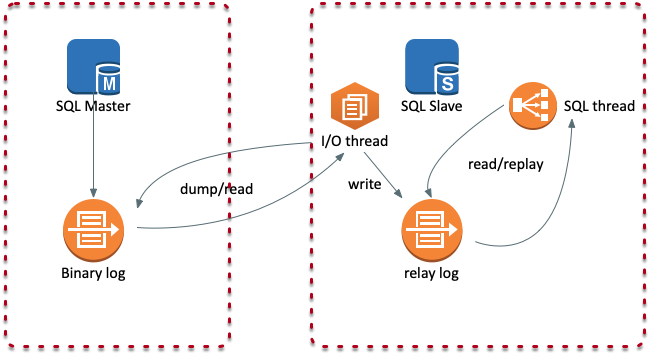
上面的描述我们通过字面简单进行了理解:当 I/O 线程仍在排队等待一件新事件时,Seconds_Behind_Master 有可能返回一个较大的随机值,直到 SQL 线程完成该事件的重放。
那么这里我们已经可以确认了,MySQL 是会出现这个情况的,并且是正常的,至少这个报警轰炸是不用特别担心了。那为什么忽然就炸出来了呢,在后面几分钟后我们得到了几个信息,确认了原因:
- 该报警原先的设置是 X 时间内只发送第 N 条报警:X 时间内并不一定总会出现 >= N 次的随机
Seconds_Behind_Master飙升(并且被监控插件获取到);即使出现 >= N 次,在 X 时间内也只会发送一条报警,所以这个问题一直并没有被注意到; - 从报警平台的同事了解到,确实在维护过程中,报警策略匹配有问题,导致
X 时间内只发送第 N 条这个策略没有生效,所有报警都发了出来; - 如前述,某同事确实做了策略变更,该变更可以明确是错的,但跟上述的轰炸没有正相关。
这个时候我们整体的原因已经比较清楚了,恢复生效的策略,并同步通告相关产品具体的情况,让产品安心是我们服务的目标之一。
但这里也暴露了几个问题:
- 报警平台维护变更出现了一定的问题,导致策略失效;
- 部分 DBA 同学在某些环节对系统的了解并不够完整、也不够专业(我们都需要不断学习积累的,我自己也是学习中,能理解);
- DBA 同学在做策略变更的时候也没有在团队内部进行同步,存在管理和规范遵守上的问题;
以上问题需要我们进行反思,并在团队内进行解决。但是 MySQL Seconds_Behind_Master 是否还有监控的价值呢?对可能导致 Seconds_Behind_Master 异常的情况这里做个简单的总结:
- Replication 启动时,Slave 会在主库执行
SELECT UNIX_TIMESTAMP()并进行主库和从库的系统时间差值对比,以避免由于系统时间差异对于Seconds_Behind_Master的时间产生影响。但如果是 Replication 启动后的时间异常,还是会对Seconds_Behind_Master产生影响,因此确保系统时间的同步非常重要(ntpd); - 当 Master 和 Slave 间的网络较差时,I/O 线程不能快速的获取 Binlog Events,SQL 线程处理速度是有可能超过 I/O 线程的,那么这个时候即使是 0,也不代表主从同步是正常的。(良好的网络环境是主从同步的基础保障)
- 当 I/O 线程被关闭时,该值可能为 NULL。(可以理解为特殊情况);
Seconds_Behind_Master 怎么用?
结合以上情况,我认为 Seconds_Behind_Master 还是一个很重要的同步是否落后的参考值的,只是可能我们可以做得更完善一些,比如在获取的时候,可以通过二次获取进行判断,当获取到较大值时,再次获取一次当前值进行确认。
另外,如果需要较为严格的同步监控,建议通过 Binglog 的位置:
- Master_Log_file/Read_Master_Log_Pos
- Relay_Master_Log_File/Exec_Master_Log_Pos
进行判断,如果(Relay_Master_Log_File, Exec_Master_Log_Pos) 和 (Relay_Master_Log_File, Read_Master_Log_Pos)位置相等且 Seconds_Behind_Master=0,那么我们可以认为目前的同步是「同步」的。(开启 gtid 的话,比对 Executed_Gtid_Set 我认为也是没有毛病的)
The End
后续相关技术内容的总结,也会逐步更新至微信平台(微信目前确实也是技术内容流转的一个好渠道),欢迎关注个人公众号(也算给自己立个 flag 吧,希望 flag 永不倒):

您可能还喜欢以下文章
- TiDB DM 数据库同步 STEP BY STEP
- 记一次 TiDB 时区设置异常问题排查
- Obsidian 接入 DeepSeek API 指南:Text Generator 插件配置教程
- 阿里云域名解析被转移,让我穿越回了 15 年前
- 网易游戏 MySQL-MongoDB 运维及 DBA 招聘
相关评论
comments powered by Disqus